
What the benchmarks don’t tell you about smart meter imputation at production scale.
Arcadia’s Udit Garg recently put a sharp number on a problem the energy data industry has danced around for years: generic AI achieves 90–95% accuracy in energy data tasks, but production energy management requires 98–99%. That 4–8 point gap sounds modest. At the scale of millions of interval reads per day across 10,000+ utilities, it isn’t.
I’ve been working on the interval data problem from the utility side — building load forecasting and gap-filling pipelines on AMI data, and more recently on student time-series data with similar missingness patterns. The research literature has caught up to what practitioners already know: the accuracy gap in smart meter imputation is real, it’s structural, and it gets dramatically worse in exactly the cases that matter most.
What the Benchmarks Actually Show
A January 2025 benchmark paper from the University of Luxembourg (Bridging Smart Meter Gaps, Sartipi et al., arXiv:2501.07276) evaluated 16 models — statistical, ML, and five Time Series Foundation Models including TimeGPT, Chronos, Moirai, and TimesFM — against residential smart meter data with gaps ranging from 30 minutes to 24 hours.
The headline result: Time Series Foundation Models can outperform traditional approaches on short gaps. Chronos and TimeGPT showed meaningful accuracy gains over ARIMA and linear interpolation in the 30-minute to 2-hour range.
But the finding that practitioners need to pay attention to is buried in Section 5: performance degrades substantially as gap length approaches 24 hours, and the computational cost of foundation models may not justify their gains for the short gaps where simpler methods already perform adequately.
This is the inverse of what energy data platforms need. The easy gaps — 30 minutes, maybe an hour — are the ones where billing accuracy is forgiving and business impact is low. The hard gaps are the multi-day outages from meter communication failures, utility system errors, or storms. Those are exactly where foundation models degrade, where rule-based approaches collapse, and where Arcadia’s documented “garbage in, garbage out” problem bites hardest.
Three Failure Modes That Compound the Gap
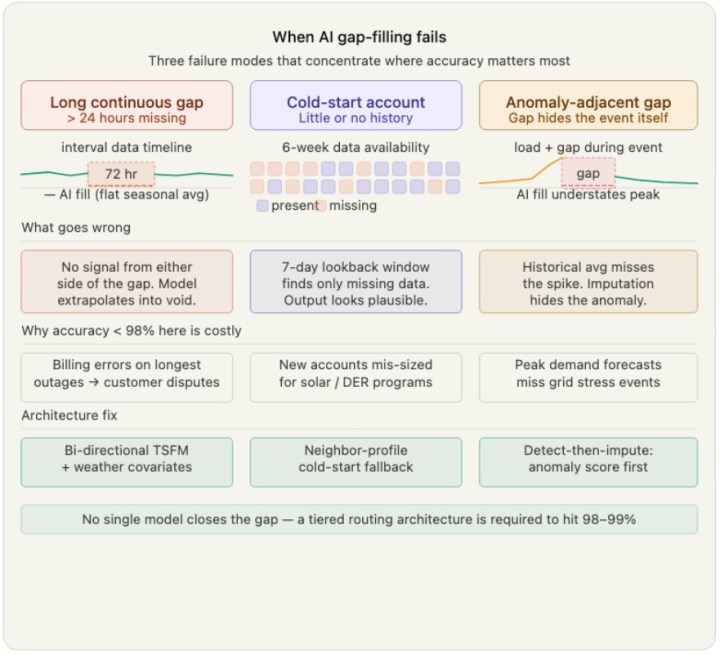
The research literature, combined with production experience, points to three structural failure modes that together explain why 90–95% overall accuracy masks far worse performance in consequential cases:
1. Long continuous gaps. A 2023 paper on building energy imputation (Filling time-series gaps using image techniques, arXiv:2307.05926) tested models on 30% continuous missing data and found that “none of the models are able to generate results of satisfactory quality” — particularly for weather-dependent meters without external covariates. This isn’t a modeling failure. It’s a fundamental information problem: when you’re missing three days of a residential account in January, no amount of model sophistication recovers the ground truth without exogenous weather and behavioral signals.
2. Cold-start accounts. Production AMI data isn’t just an established account with one gap — it’s thousands of new meters, migrated accounts, and low-frequency nodes with thin or absent history. This isn’t unique to electricity; across the broader utility landscape, data scarcity is structural. For instance, a real-world smart water meter deployment dataset (arXiv:2506.08882) shows missingness rates ranging from 20% to 79% across buildings, with some accounts having no usable history at all. Standard ML approaches that rely on rigid 7-day lookback windows… produce meaningless outputs for these cold-starts. The imputed values look plausible, but they are fundamentally wrong.
3. Anomaly-adjacent gaps. The most pernicious case: missing data that co-occurs with the events that caused the gap — a meter failure during a demand spike, an outage during an extreme weather event. Imputing these gaps with historical average patterns systematically underestimates the true consumption in exactly the scenarios where accurate billing and grid planning matter most. A 2020 ensemble paper (Jung et al., Sensors) noted that “methods have achieved limited success in imputing electric energy consumption data because the period of data missing is long and the dependency on historical data is high” — which is a precise description of the anomaly-adjacent case.
What Actually Closes the Gap
The literature and production experience converge on the same answer: no single model closes the gap across all gap types. What does work is a tiered imputation architecture that routes gap-filling decisions by gap type rather than applying one method universally:
- Short random gaps (< 2 hours): seasonal naive or Kalman smoothing outperforms heavier models at a fraction of the compute cost
- Medium gaps (2–24 hours) with rich history: TSFM-based forward/backward interpolation with uncertainty quantification
- Long gaps or cold-start accounts: hybrid approach combining sparse external signals (weather, similar-profile neighbors, utility estimated reads) with explicit uncertainty flagging — not a point estimate presented as ground truth
- Anomaly-adjacent gaps: detect-then-impute pipeline, where anomaly scoring precedes imputation method selection
The Sartipi benchmark’s forward/backward interpolation approach — predicting from both sides of the gap and weighting toward each boundary — is a sound architectural pattern for the medium-gap case. But it requires an upstream routing layer that the benchmark doesn’t implement.
Why This Matters for Energy Platforms
Arcadia’s own description of their validation layer — nearly 100,000 automated audit rules, ensemble-LLM cross-checks on the 2–3% of cases where systems disagree — is exactly the right instinct. The 98–99% accuracy bar isn’t achievable with a single model. It requires layered validation that knows which cases are high-risk and routes them accordingly.
The gap-filling problem is a microcosm of the broader energy AI accuracy challenge: aggregate metrics look fine; the failures concentrate in the tail cases that determine whether a customer gets an accurate bill, whether a load forecast is reliable during peak demand, and whether a grid operator can trust interval data for DER dispatch.
Getting the easy cases right is table stakes. The real problem is knowing when you’re in a hard case — and having an architecture that handles it differently.
I’ve been working on interval data pipelines and time-series imputation for energy and utility applications. Happy to compare notes on gap-filling architectures — particularly the cold-start and anomaly-adjacent cases that production systems see most.
